The term "RAID" was coined in 1987
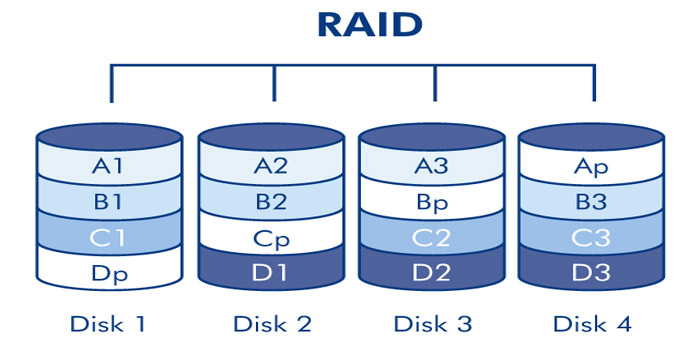
(RAID) Possible server configurations using RAID ...
The term "RAID" was proposed in 1987 by Petterson (David A. Patterson), Gibson (Garth A. Gibson) and
Katz (Randy H. Katz) as an abbreviation for the English Redundant Array of Inexpensive Disks
("redundant array of inexpensive disks").
-
Possible using RAID ...
-
In their presentation, they argued for their invention with the relatively low cost of an array of cheap
disks designed for personal computers, in comparison with high-capacity disks, which they called «SLED»
(Single Large Expensive Drive).
Later, the interpretation of the term changed to Redundant Array of Independent Disks
(redundant array of independent Disks (independent) disks), because expensive server disks were
often used in arrays.
-
RAID 0
-
RAID 0 (striping — "striping") is a disk array of two or more hard drives without redundancy.
The information is divided into fixed-length data blocks and written to both/several disks in
turn, that is one block to the first disk, and the second block to the second disk, respectively.
The level is based on the division of information into blocks with simultaneous recording of different
blocks on different disks. The technology significantly increases the speed of reading and writing,
while the user can use the total the volume of all drives. There is one drawback — fault tolerance tends
to zero, i.e. to restore the damaged HDD/SSD will no longer be possible.
To implement such a solution, you need at least 2 disks.
-
RAID 1
-
RAID 1 (mirroring— is an array of two disks that are complete copies of each other.
Not to be confused with RAID 1+0 (RAID 10), RAID 0+1 (RAID 01) arrays, which use more
complex mirroring mechanisms.
This method is already based on the complete duplication of data into several media. The principle
is steep and reinforced concrete in terms of reliability, but when using two disks with a capacity
of 2 TB, you you get only one worker. The second one becomes invisible to the system — only to the
RAID controller. The process also does not provide any advantages in speed, but fault tolerance
increases several times. If one of the HDD/SSD has been ordered to live for a long time, its full
cast is on the second medium.
The processes of writing, deleting and copying occur in parallel. There is one caveat from this:
the information has been erased from one HDD, it disappears automatically on the second one.
To implement such a solution, you need at least 2 disks.
-
RAID 2
-
RAID 2 arrays of this type are based on the use of Hamming code. Disks are divided into two groups:
for data and for error correction codes, and if the data is stored on two disks, then it is necessary
to store correction codes at least three disks. The total number of disks in this case will be equal
to three disks. The data is distributed across the disks intended for storing information in the same
way as in RAID 0, that is, they are divided into small blocks according to the number of disks.
The remaining disks store error correction codes, according to which, in case of failure of any hard disk,
it is possible information recovery.
To implement such a solution, you need at least 3 disks.
-
RAID 3
-
In a RAID 3 disk array, data is split into chunks smaller than a sector (split into bytes)
and distributed on two disks. Another disk is used to store parity blocks.
This unified format for organizing a disk array uses striping and allocates one disk from an
available pool storage devices for storing parity information, which is responsible for checking
the integrity by determining whether data was lost or overwritten when it was directly moved from
one storage location to another or at the time of transfer between computers.
To implement such a solution, you need at least 3 disks.
-
RAID 4
-
RAID 4 is similar to RAID 3, but differs from it in that data is split into blocks, not bytes.
Thus, it was partially possible to "defeat" the problem of low data transfer rate of a small volume.
The recording is being made it is slow due to the fact that the parity for the block is generated
during recording and is written to a single disk.
To implement such a solution, you need at least 3 disks.
-
RAID 5
-
RAID 5 is a disk array with alternating data blocks and parity control. The main disadvantage of RAID
levels from 2nd to 4th is the inability to produce parallel write operations, since a separate control
disk is used to store parity information.
RAID 5 does not have this disadvantage. Data blocks and checksums are cyclically written to all disks of
course, there is no asymmetry in the disk configuration. The technology is considered one of the most
widespread and safe, because it works on the principles of parity and alternation. To create a fifth
Raid, you must have at least 3 disks.
During recording, the data is divided into blocks, with a special condition: to one of the disks, called
a block parity (Parity Drive/PD) information is written for further recovery. In case something went wrong
by the fault of the user, or the obsolescence of the drives as a whole.
The convenience of RAID 5 is that it can be implemented both hardware and software using the appropriate
utilities supplied with the OS. However, any intelligent specialist will say that the hard-core option
is much safer.
To implement such a solution, you need at least 4 disks.
-
RAID 6
-
RAID 6 is an array of four or more disks with P+Q or DP parity checking, designed to protect from data
loss when two hard drives in the array fail at once. This reliability is achieved by due to reduced
performance and reduced capacity, two steps are needed to restore information computing operations, and
two disks in the array are not used to store data, but to control them integrity and failure recovery.
In many ways, this technology duplicates the features of RAID 5, but the data for recovery is copied to
two backup media at once. The second parity disk is, in fact, a duplicate link, to be sure.
The principle of its operation is based on the Reed-Solomon code, and therefore the second drive is
labeled as Q or RS.
Thanks to this principle, the server owner can painlessly transfer the untimely death of a pair of
HDD/SSD at once. That's just for the implementation of RAID 6, you will need 4 disks already.
-
RAID 7
-
RAID 7 is a registered trademark of Storage Computer Corporation, a separate level RAID is not.
The structure of the array is as follows: two disks store data, one disk is used for storage blocks
of parity. Writing to disks is cached using RAM, the array itself requires mandatory UPS; in case of
power outages, data corruption occurs.
To implement such a solution, you need at least 2 disks.
-
RAID 10
-
RAID 10 (RAID 1+0) is a mirrored array in which data is written sequentially to several disks, as in RAID 0.
This architecture is a RAID 0 array, the segments of which are RAID 1 arrays instead of individual disks.
Accordingly, an array of this level must contain at least 4 disks (and always an even number).
RAID 10 combines into high fault tolerance and performance.
This technology combines the advantages of RAID 1 and RAID 0 in virtualization mode, which provides
high speed recovery, excellent reliability and performance.
RAID 10 is a nested RAID type that combines RAID 1 and RAID 0, hence its name. Many professionals they
prefer to write it as RAID 1+0. The array first splits the data into blocks (RAID 0), and then creates for
them mirroring on separate disks (RAID 1). Remember, this is not the same as RAID 0 + 1, which works in the
opposite direction, first creating a mirror image of the data, and then splitting it into blocks.
To implement such a solution, you need at least 4 disks.
-
RAID 50
-
This configuration takes all the advantages of RAID 5 (parity) and RAID 0 (striping) to improve performance
without reducing protection indicators. But only if you have 6 disks or more.
RAID organization allows you to survive a breakdown of up to 4 disks if they are hanging in
a separate RAID 5 array. To implement such a solution, you need at least 6 disks.
-
RAID 60
-
RAID 60 (also called RAID 6+0) is a combined set of RAID 0 and RAID 6 arrays, offering the user
improved performance and processing speed of the array data. This combination has not been widely
used, but it has some advantages, among which it is especially possible to highlight the possibility
of maintaining operability (no delays in calculating and writing a large number of parity bits) while
increasing the total volume in parallel spaces.
Striping ("striping") helps to increase throughput and performance without adding additional
disks are attached to each RAID 6 set, which, in turn, reduces data availability. RAID 60 increases
performance RAID 6, despite the fact that RAID 60 is noticeably slower than RAID 50, especially in
terms of "writing" data.
To implement such a solution, you need at least 8 disks.
-
Lifecycle Controller (LCC)
-
LCC Dell PowerEdge
-
The Dell PowerEdge server management solution is based on an integrated Lifecycle Controller (LCC).
LCC is a lightweight operating system that runs from iDRAC to receive instructions from the systems management.
It also serves as a direct point for updates and helps to perform automated tasks
in in accordance with the instructions for creating and maintaining workable servers.
-
The controller iDRAC
-
The iDRAC controller is hardware integrated into the server motherboard and, like other BMC solutions,
has its own processor, memory, network connection and access to the system bus.
iDRAC provides remote access to the system console (keyboard and screen), allowing access to the BIOS
systems over the Internet when the server is restarted. The main functions of iDRAC include power management,
access to virtual media and remote console capabilities. These functions give administrators the ability to
customize the computer is as if they were sitting in front of a local console.
HTTP methods

General HTTP methods
An HTTP method is safe if it does not change the state of the server. In other words,
a safe method performs read-only operations.
A GET request is sent via an HTML form, and by many other programs, scripts.
-
HTTP methods
-
General HTTP methods
-
The correct implementation of the secure method is the responsibility of the server application,
the web server Apache, nginx, IIS itself will not be able to protect. This means that the application
should not allow changing the server state by GET requests.
-
Method GET
-
The GET method requests a representation of a resource. Requests using this method can only retrieve data.
-
Method POST
-
The POST method is intended to send data to the server. Often causes a state change or some side effects
on the server. The POST request is usually sent via an HTML form, and many other programs, scripts.
-
Method HEAD
-
The HEAD method requests a resource in the same way as the GET method, but without a response body.
The HTTP HEAD method requests headers identical to those that would be returned if the specified resource
were requested using the HTTP GET method. Such a request may be made before downloading a large
resource, for example to save bandwidth.
The response to the HEAD method must not contain a body. If it does not, it should be ignored.
Even so, entity headers describing the contents of the body, such as Content-Length,
must be included in the response. They do not apply to the body of the response to a HEAD request, which must be empty,
but rather to the body of the response received for a similar request using the GET method.
-
Method PUT
-
The PUT method replaces all current representations of a resource with the request data. Typically,
PUT creates a new resource or replaces a representation of the target resource with the data provided in
the request body.
-
Method DELETE
-
The DELETE method deletes the specified resource. Example of a DELETE header /file.html HTTP/1.1
-
Method CONNECT
-
The CONNECT method establishes a "tunnel" to the server specified by the resource.
-
Method OPTIONS
-
The OPTIONS method is used to describe the connection parameters to a resource.
-
Method TRACE
-
The TRACE method calls the returned test message from the resource.
-
Method PATCH
-
The PATCH method is used to partially modify a resource.
To indicate that the server supports PATCH, you can add this method to the Allow (en-US) or
Access-Control-Allow-Methods (for CORS) response headers.
DNS hosting records

DNS (Domain Name System) is the "phone book" of the Internet. It uses IP addresses as phone numbers, and domains
as contact names. In such a book, you can enter not only a "phone number", but also additional information about
a contact ("e-mail", "place of work", etc.).
-
DNS hosting records
-
Recording A
The A (address) record is one of the key resource records on the Internet. It is needed to link a domain to the
server's IP address.
Until the A record is registered, your site will not work.
When you enter the name of a site in the browser's address bar, it is the A record that DNS uses to determine
from which server your site should be opened.
-
Recording AAAA
AAAA (IPv6 address record) is a record that works the same way as the A record — it links a domain to the server's
IP address. However, it is only suitable for IPv6 addresses (like 7628:0d18:11a3:09d7:1f34:8a2e:07a0:765d).
-
Recording CNAME
CNAME (Canonical name) is a record that is responsible for linking subdomains (for example, www.site.com) to the
canonical domain name (site.com) or another domain.
The main function of CNAME is to duplicate domain resource records (A, MX, TXT) for different subdomains.
-
Recording MX
MX record what is it? This is a record that is responsible for the server through which the mail will work.
MX records are critically important for the mail to work. Thanks to them, the sending party "understands"
which server to send mail to for your domain.
-
Recording TXT
TXT (Text string) is a record that contains any text information about a domain. TXT records are used for
various purposes: confirming domain ownership, ensuring email security, and confirming an SSL certificate.
It is often used to check domain ownership when connecting additional services, as well as a container for
an SPF record and a DKIM key. You can specify an unlimited number of TXT records, as long as they do not conflict
with each other.
-
Recording SPF
SPF record (Sender Policy Framework) contains information about the list of servers that have the right to send
letters on behalf of a given domain. Allows you to avoid unauthorized use. The SPF setting is specified in the
TXT record for the domain.
-
Recording NS
NS record (Authoritative name server) points to DNS servers that are responsible for storing the remaining
resource records of the domain. The number of NS records must strictly correspond to the number of all servers
servicing it.
Critically important for the operation of the DNS service.
-
Recording PTR
PTR is a reverse DNS record that links the server's IP address to its canonical name (domain). The PTR record is
used for mail filtering.
-
Recording SOA
SOA (Start of Authority) is the initial zone record that specifies which server stores reference information
about a domain name. It is critical for the operation of the DNS service.
Recent Posts
RAID Controller
HTTP Headers
HTTP methods
DNS records
